LimeADPD
Indirect Learning Architecture
The simplified block diagram of an indirect learning architecture is given in Figure 1. Please note that RF part in both TX (up to PA input) neither in RX (back to base-band frequency) paths is shown for simplicity.
A delay line compensates ADPD loop (yp(n) to x(n)) delay. Post-distorter is trained to be inverse of power amplifier. Predistorter is a simple copy of post-distorter. When converged:
hence, PA is linearized.
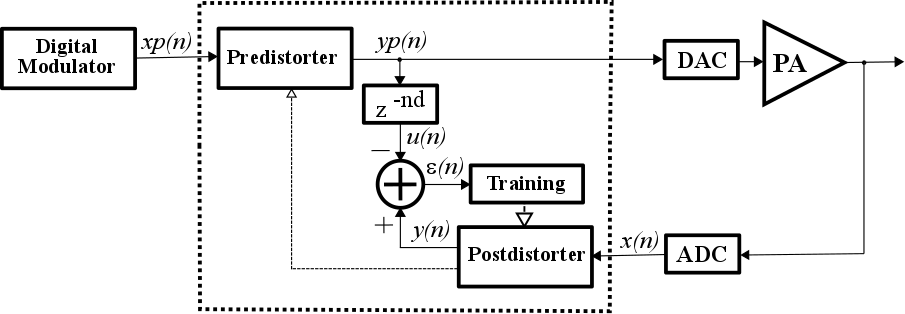
Figure 1: Indirect learning architecture
Complex Valued Memory Polynomial
LimeADPD algorithm is based on modelling nonlinear system (PA and its inverse in this case) by complex valued memory polynomials which are in fact cut version of Volterra series which is well known as general nonlinear system modelling and identification approach. In this particular case “cut version” means the system can efficiently be implemented in real life applications.
For a given complex input:
complex valued memory polynomial produces complex output:
where:
are the polynomial coefficients while e(n) is the envelope of the input. For the envelope calculation, two options are considered, the usual one:
and the squared one:
Usually, squared one is used in ADPD applications since it is simpler to calculate and in most cases provides even better results.
In the above equations, N is memory length while M represents nonlinearity order. Hence, complex valued memory polynomial can be taken into account both system memory effects and the system nonlinearity.
LimeADPD Equations
Based on discussions given in previous sections and using signal notations of Figure 1, ADPD pre-distorter implements the following equations:
while post-distorter does similar:
Note that pre-distorter and post-distorter share the same set of complex coefficients wij. Delay line is simple, and its output is given by:
Training Algorithm
ADPD training algorithm alters complex valued memory polynomial coefficients wij in order to minimize the difference between PA input yp(n) and y(n), ignoring the delay and gain difference between the two signals. Instantaneous error shown in Figure 1 is calculated as:
Training is based on minimising Recursive Least Square (RLS) E(n) error:
by solving linear system of equations:
Any linear equation system solving algorithm can be used. Lime ADPD involves LU decomposition. However, iterative techniques such as Gauss – Seidel and Gradient Descent have been evaluated as well. LU decomposition is adopted in order to get faster adaptation and tracking of the ADPD loop.